构建一个简易的火车票售票系统,Newbe.Claptrap框架用例,第一步——业务分析
Newbe.Claptrap 框架非常适合于解决具有并发问题的业务系统。火车票售票系统,就是一个非常典型的场景用例。
本系列我们将逐步从业务、代码、测试和部署多方面来介绍,如何使用 Newbe.Claptrap 框架来构建一个简易的火车票售票系统。
吹牛先打草稿
让我们来首先界定一下这个简易的火车售票系统所需要实现的业务边界和性能要求。
业务边界
该系统仅包含车票的余票管理部分。即查询剩余座位,下单买票减座。
而生成订单信息,付款,流量控制,请求风控等等都不包含在本次讨论的范围中。
业务用例
- 查询余票,能够查询两个车站间可用的车次以及剩余座位数量。
- 查询车次对应的车票余票,能够查询给定的车次,在各个车站之间还有多少剩余座位。
- 支持选座下单,客户能够选择给定的车次及座位,并下单买票。
性能要求
- 查询余票和下单购票消耗平均不得超过 20ms。该时间仅包含服务端处理时间,即页面网络传输,页面渲染等等不是框架关心的部分不计算在内。
- 余票查询可以存在延时,但不是超过 5 秒钟。延时,即表示,可能查询有票,但是下单无票的情况是被允许的。
难点分析
余票管理
火车票余票管理的难点,其实就在于其余票库存的特殊性。
普通的电商商品,以 SKU 为最小单位,每个 SKU 之间相互独立,互不影响。
例如:当前我正在售卖原产自赛博坦星球的阿姆斯特朗回旋加速炮,红色和白色两款分别一万个。那么用户在下单时,只要分别控制红色和白色两款的库存分别不超卖即可。他们之间没有相互关系。
但是火车票余票,却有所不同,因为余票会受到已卖票起终点而受到影响。下面结合一个简单的逻辑模型,来详细的了解一下这种特殊性。
现在,我们假设存在一个车次,分别经过 a,b,c,d 四个站点,同时,我们简化场景,假设车次中只有一个座位。
那么在没有任何人购票之前,这个车次的余票情况就如下所示:
| 起终点 | 余票量 |
|---|---|
| a,b | 1 |
| a,c | 1 |
| a,d | 1 |
| b,c | 1 |
| b,d | 1 |
| c,d | 1 |
如果现在有一位客户购买了一张 a,c 的车票。那么由于只有一个座位,所以,除了 c,d 其他的余票就都没有。余票情况就变成了如下所示:
| 起终点 | 余票量 |
|---|---|
| a,b | 0 |
| a,c | 0 |
| a,d | 0 |
| b,c | 0 |
| b,d | 0 |
| c,d | 1 |
更直白一点,如果有一位客户购买了全程车票 a,d,那么所有的余票都将全部变为 0。因为这个座位上始终都坐着这位乘客。
这也就是火车票的特殊性:同一个车次的同一个座位,其各个起终点的余票数量,会受到已售出的车票的起终点的影响。
延伸一点,很容易得出,同一车次的不同座位之间是没有这种影响的。
余票查询
正如上一节所述,由于余票库存的特殊性。对于同一个车次 a,b,c,d,其可能的购票选择就有 6 种。
并且我们很容易就得出,选择的种类数的计算方法实际上就是在 n 个站点中选取 2 个的组合数,即 c(n,2) 。
那么如果有一辆经过 34 个站点的车次,其可能的组合就是 c(34,2) = 561 。
如何高效应对可能存在的多种查询也是该系统需要解决的问题。
Claptrap 逻辑设计
Actor 模式是天生适合于解决并发问题的设计模式。基于该理念之上的 Newbe.Claptrap 框架自然也能够应对以上提到的难点。
最小竞争资源
类比多线程编程中“资源竞争”的概念,这里笔者提出在业务系统中的“最小竞争资源”概念。借助这个概念可以很简单的找到如何应用 Newbe.Claptrap 的设计点。
例如在笔者售卖阿布斯特朗回旋加速炮的例子中,同款颜色下的每个商品都是一个“最小竞争资源”。
注意,这里不是说,同款颜色下的所有商品是一个“最小竞争资源”。因为,如果对一万个商品进行编号,那么抢购一号商品和二号商品,本身其实不存在竞争关系。因此,每个商品都是一个最小竞争资源。
那么在火车票余票的例子中,最小竞争资源则是:同一车次上的同一个座位。
正如上面所述,同一车次上的同一座位,在选择不同的起终点是,余票情况时存在竞争关系的。具体一点,比如笔者想购买 a,c 的车票,而读者想买 a,b 的车票。那么我们就有竞争关系,我们只会有一个人能够成功的购买到这个“最小竞争资源”。
这里有一些笔者认为可用的例子:
- 在一个只允许单端登录的业务系统中,一个用户的登录票据就是最小竞争资源
- 在一个配置系统中,每个配置项都是最小竞争资源
- 在一个股票交易市场中,每个买单或者卖单都是最小竞争资源
这是笔者自己的臆造词,没有参考其他资料,如果有类似资料或者名词可以佐证该内容,也希望读者可以留言说明。
最小竞争资源 与 Claptrap
之所以要提及“最小竞争资源”,是因为在设计 Claptrap 的 State 时,区别最小竞争资源是对系统设计的一个重要依据。
这里列出一条笔者的结论:Claptrap 的 State 至少应该大于等于“最小竞争资源”的范围。
结合阿布斯特朗回旋加速炮的例子,如果同款颜色的所有商品设计在同一个 Claptrap 的 State 中(大于最小竞争资源)。那么,不同用户购买商品就会相互影响,因为,Claptrap 基于的 Actor 模式是排队处理请求的。也就是说,假设每个商品需要处理 10ms,那么最快也需要 10000 * 10 ms 来处理所有的购买请求。但如果每个商品都进行编号,每个商品设计为单独的 Claptrap 的 State。那么由于他们是互不相关的。卖掉所有商品,理论上就只需要 10ms。
也就是说:如果 Claptrap 的 State 大于最小竞争资源的范围,系统不会有正确性的问题,但可能有一些性能损失。
再进一步,前文提到在火车售票的例子中,同一车次上的同一个座位是最小竞争资源,因此,我们可以将这个业务实体设计为 Claptrap 的 State 。但如果设计范围比这个还小呢?
例如:我们将 Claptrap 的 State 设计为同一车次上同一座位在不同起终点的余票。那么,就会遇到一个很传统的问题:“如何确保分布式系统中数据的正确性”。对于这点,笔者无法展开来说,因为笔者也说不清楚,就只是草率的丢下一句结论:“如果 Claptrap 的 State 小于最小竞争资源的范围,Claptrap 间的关系将会变得难以处理,存在风险。”
Claptrap 主体设计
接下来,结合上面所述的理论。我们直接丢出设计方案。
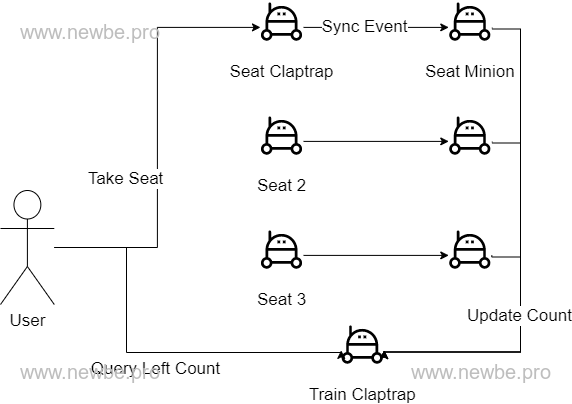
将同一车次上的每个座位都设计为一个 Claptrap - SeatGrain
该 Claptrap 的 State 包含有一个基本信息
| 类型 | 名称 | 说明 |
|---|---|---|
| IList<int> | Stations | 途径车站的 id 列表,开头为始发站,结尾为终点站。主要购票时进行验证。 |
| Dictionary<int, int> | StationDic | 途径车站 id 的索引反向字典。Stations 是 index-id 的列表,而该字典是对应的 id-index 的字典,为了加快查询。 |
| List<string> | RequestIds | 关键属性。每个区间上,已购票的购票 id。例如,index 为 0 ,即表示车站 0 到车站 1 的购票 id。如果为空则表示暂无认购票。 |
有了这数据结构的设计,那么就可以来实现两个业务了。
验证是否可以购买
通过传入两个车站 id,可以查询到这个作为是否属于这个 SeatGrain 。并且查询到起终点对应的所有区间段。只要判断这个从 RequestIds 中判断是否所有的区间段都没有购票 Id 即可。若都没有,则说明可以购买。如果有任何一段上已有购票 Id,则说明已经无法购买了。
举例来说,当前 Stations 的情况是 10,11,12,13. 而 RequestIds 是 0,1,0。
那么,如果要购买 10->12 的车票,则不行,因为 RequestIds 第二个区间已经被购买。
但是,如果要购买 10->11 的车票,则可以,因为 RequestIds 第一个区间还无人购买。
购买
将起终点对应在 RequestIds 中所有的区间段设置上购票 Id 即可。
单元测试用例
可以通过以下链接来查看关于以上算法的代码实现:
将同一车次上的所有座位的余票情况设计为一个 Claptrap - TrainGran
该 Claptrap 的 State 包含有一些基本信息
| 类型 | 名称 | 说明 |
|---|---|---|
| IReadOnlyList<int> | Stations | 途径车站的 id 列表,开头为始发站,结尾为终点站。主查询时进行验证。 |
| IDictionary<StationTuple, int> | SeatCount | 关键属性。StationTuple 表示一个起终点。集合包含了所有可能的起终点的余票情况。例如,根据上文,如果该车次经过 34 个地点,则该字典包含有 561 个键值对 |
基于以上的数据结构,只需要在每次 SeatGrain 完成下单后,将对应的信息同步到该 Grain 即可。
例如,假如 a,c 发生了一次购票,则将 a,c / a,b / b,c 的余票都减一即可。
这里可以借助本框架内置的 Minion 机制来实现。
值得一提的是,这是一个比“最小竞争资源”大的设计。因为查询场景在该业务场景中不需要绝对的快速。这样设计可以减少系统的复杂度。
小结
本篇,我们通过业务分析,得出了火车票余票管理和 Newbe.Claptrap 的结合点。
后续我们将围绕本篇的设计,说明如何进行开发、测试和部署。
实际上,项目源码已经构建完毕,读者可以从以下地址获取:
特别感谢wangjunjx8868采用 Blazor 为本样例制作的界面。
