十万同时在线用户,需要多少内存?——Newbe.Claptrap框架水平扩展实验
Newbe.Claptrap 项目是笔者正在构建以反应式、Actor模式和事件溯源为理论基础的一套服务端开发框架。本篇我们将来了解一下框架在水平扩展方面的能力。
前情提要
时隔许久,今日我们再次见面。首先介绍一下过往的项目情况:
'第一次接触本框架的读者,可以先点击此处阅读本框架相关的基础理论和工作原理。'
今日主题
今天,我们来做一套实验预演,来验证 Newbe.Claptrap 框架,如何通过水平扩展的形式来适应逐渐增长的同时在线用户数。
由于此次实验涉及的内容很多,因此笔者将内容进行了归类,读者可以按照自己的兴趣阅读相关的章节:
业务需求说明
先看看今天要实现的业务场景:
- 用户通过 API 登录后生成一个 JWT token
- 用户调用 API 时验证 JWT token 的有效性
- 没有使用常规的 JWS 公私钥方式进行 JWT token 颁发,而是为每个用户单独使用 secret 进行哈希验证
- 验证看不同的在线用户需要消耗的内存情况
- 用户登录到生成 token 所消耗时间不得超过 200 ms
- tokn 的验证耗时不得超过 10 ms
吹牛先打草稿
笔者没有搜索到于“在线用户数”直接相关的理论定义,因此,为了避免各位的理解存在差异。笔者先按照自己的理解来点明:在线用户数到底意味着什么样的技术要求?
未在线用户若上线,不应该受到已在线用户数的影响
如果一个用户登��录上线需要消耗 100 ms。那么不论当前在线的用户数是十人还是百万人。这个登录上线所消耗的时间都不会明显的超过 100 ms。
当然,有限的物理硬件肯定会使得,当在线用户数超过一个阈值(例如两百万)时,新用户登录上线会变慢甚至出错。
但是,增加物理机器就能提高这个阈值,我们就可以认为水平扩展设计是成功的。
对于任意一个已在线用户,得到的系统性能反馈应当相同
例如已在线的用户查询自己的订单详情,需要消耗 100 ms。那么当前任何一个用户进行订单查询的平均消耗都应该稳定在 100 ms。
当然,这里需要排除类似于“抢购”这种高集中性能问题。此处主要还是讨论日常稳定的容量增加。(我们以后会另外讨论“抢购”这种问题)
具体一点可以这样理解。假设我们做的是一个云笔记产品。
那么,如果增加物理机器就能增加同时使用云笔记产品的用户数,而且不牺牲任何一个用户的性能体验,我们就认为水平扩展设计是成功的。
在此次的实验中,若用户已经登录,则验证 JWT 有效性的时长大约为 0.5 ms。
调用时序关系

简要说明:
- 客户端发起登录请求将会逐层传达到 UserGrain 中
- UserGrain 将会在内部激活一个 Claptrap 来进行维持 UserGrain 中的状态数据。包括用户名、密码和用于 JWT 签名的 Secret。
- 随后的生成 JWT 生成和验证都将直接使用 UserGrain 中的数据。由于 UserGrain 中的数据是在一段时间内是“缓存”在内存中的。所以之后的 JWT 生成和验证将非常快速。实测约为 0.5 ms。
物理结构设计

如上图所示,便是此次进行测试的物理组件:
| 名称 | 说明 |
|---|---|
| WebAPI | 公开给外部调用 WebAPI 接口。提供登录和验证 token 的接口。 |
| Orleans Cluster | 托管 Grain 的核心进程. |
| Orleans Gateway | 于 Orleans Cluster 基本相同,但是 WebAPI 只能与 Gateway 进行通信 |
| Orleans Dashboard | 于 Orleans Gateway 基本相同,但增加了 Dashboard 的展示,以查看整个 Orleans 集群的情况 |
| Consul | 用于 Orleans 集群的集群发现和维护 |
| Claptrap DB | 用于保存 Newbe.Claptrap 框架的事件和状态数据 |
| Influx DB & Grafana | 用于监控 Newbe.Claptrap 相关的性能指标数据 |
此次实验的 Orleans 集群节点的数量实际上是 Cluster + Gateway + Dashboard 的总数。以上的划分实际上是由于功能设定的不同而进行的区分。
此次测试“水平扩展”特性的物理节点主要是 Orleans Cluster 和 Orleans Gateway 两个部分。将会分别测试以下这些情况的内存使用情况。
| Orleans Dashboard | Orleans Gateway | Orleans Cluster |
|---|---|---|
| 1 | 0 | 0 |
| 1 | 1 | 1 |
| 1 | 3 | 5 |
此次实验采用的是 Windows Docker Desktop 结合 WSL 2 进行的部署测试。
以上的物理结构实际上是按照最为此次实验最为复杂的情况设计的。实际上,如果业务场景足够简单,该物理结构可以进行裁剪。详细可以查看下文“常见问题解答”中的说明。
实际测试数据
以下,分别对不同的集群规模和用户数量进行测试
0 Gateway 0 Cluster
默认情况下,刚刚启动 Dashboard 节点时,通过 portainer 可以查看 container 占用的内存约为 200 MB 左右,如下图所示:

通过测试控制台,向 WebAPI 发出 30,000 次请求。每批 100 个请求,分批发送。
经过约两分钟的等待后,再次查看内存情况,约为 9.2 GB,如下图所示:
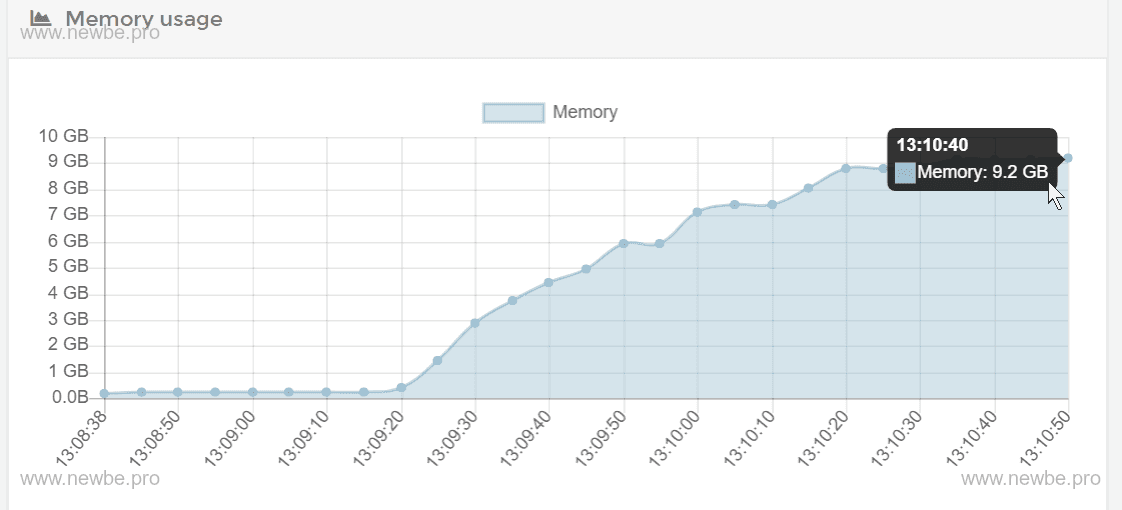
因此,我们简单的估算每个在线用户需要消耗的内存情况约为 (9.2*1024-200)/30000 = 0.3 MB。
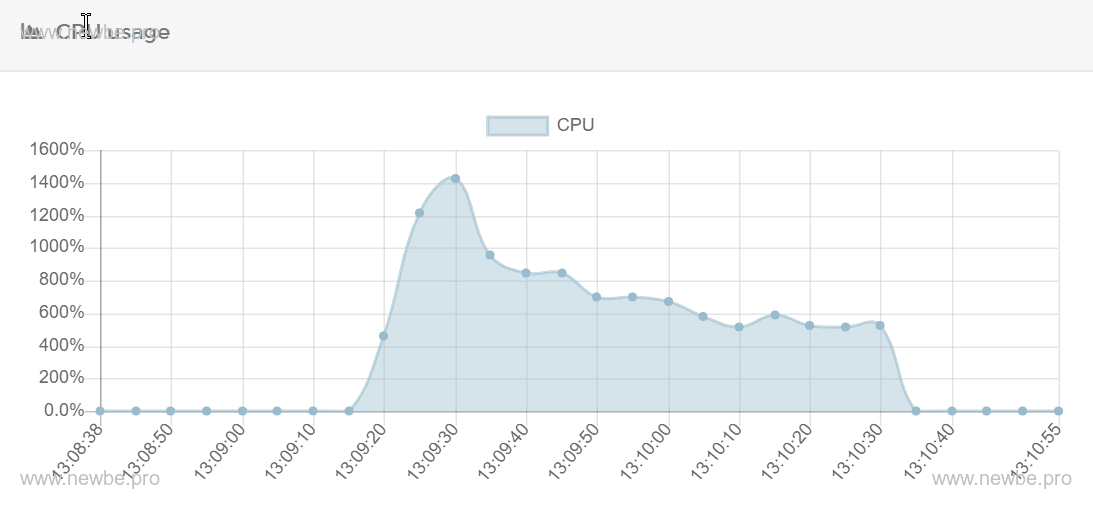
另外,可以查看一些辅助数据:
CPU 使用情况
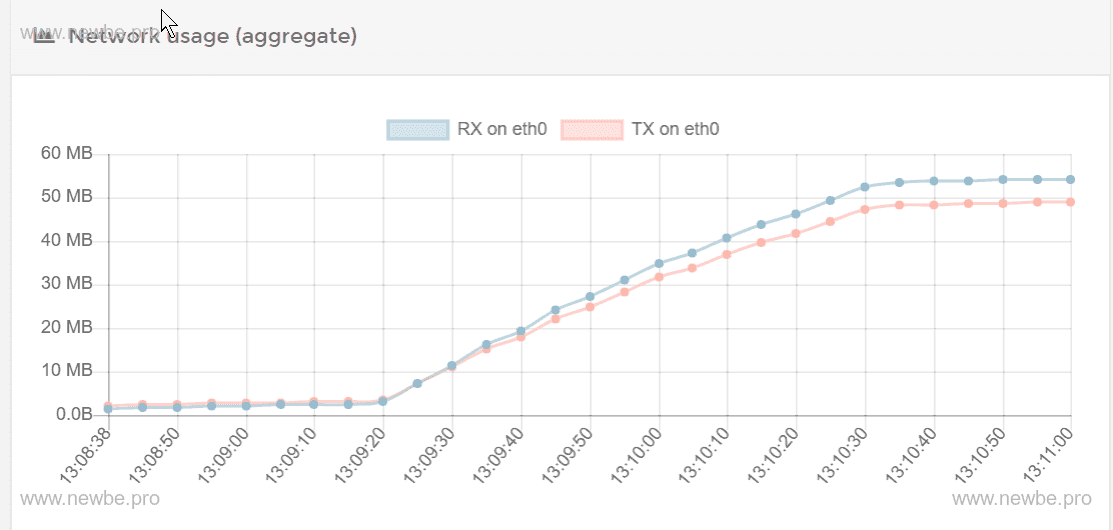
网络吞吐量
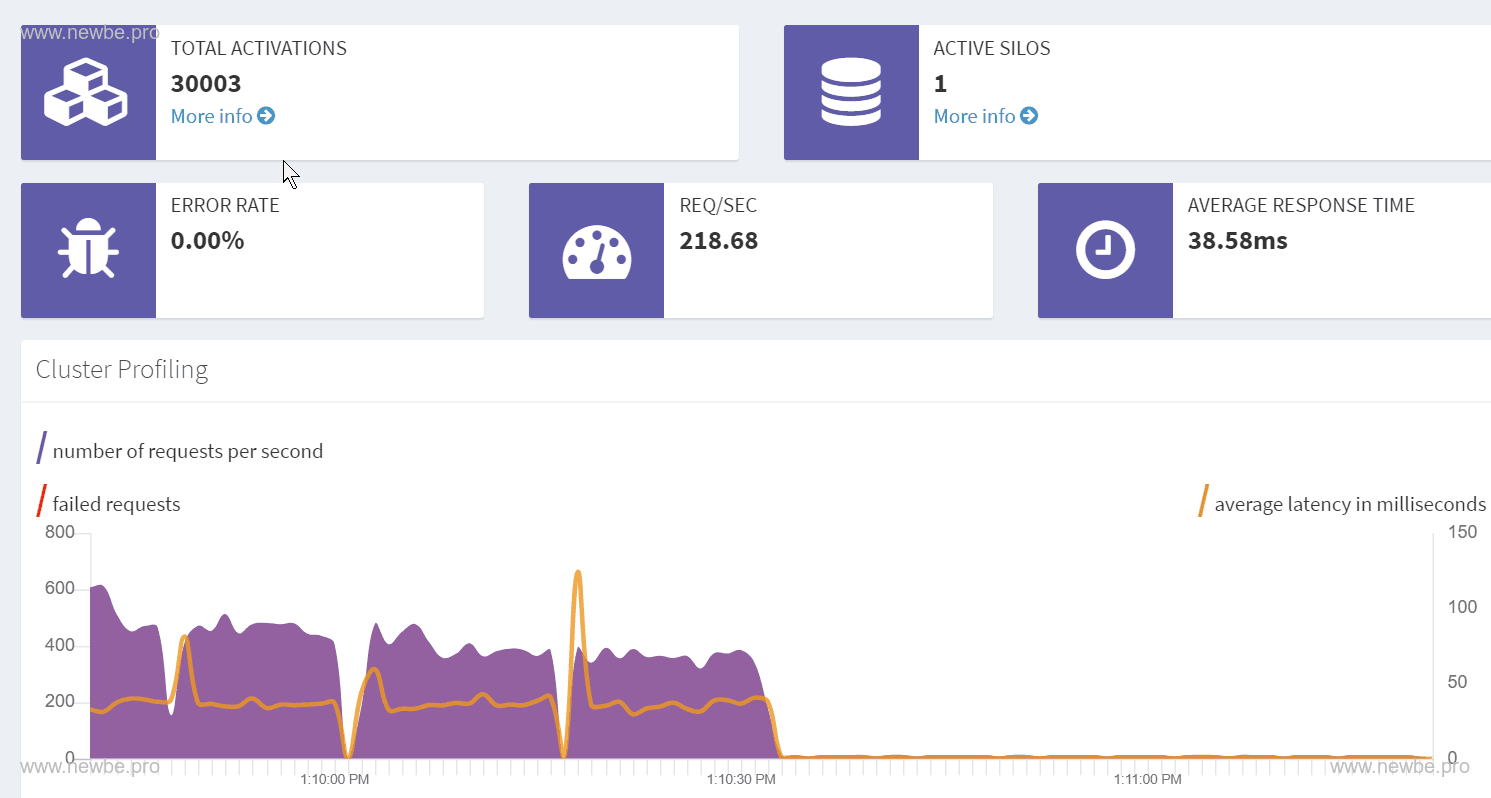
Orleans Dashboard 情况。左上角的 TOTAL ACTIVATIONS 中 30,000 即表示当前内存中存在的 UserGrain 数量,另外的 3 个为 Dashboard 使用的 Grain。
Grafana 中查看 Newbe.Claptrap 的事件平均处理时长约为 100-600 ms。此次测试的主要是内存情况,处理时长的采集时间为 30s 一次,因此样本数并不多。关于处理时长我们将在后续的文章中进行详细测试。
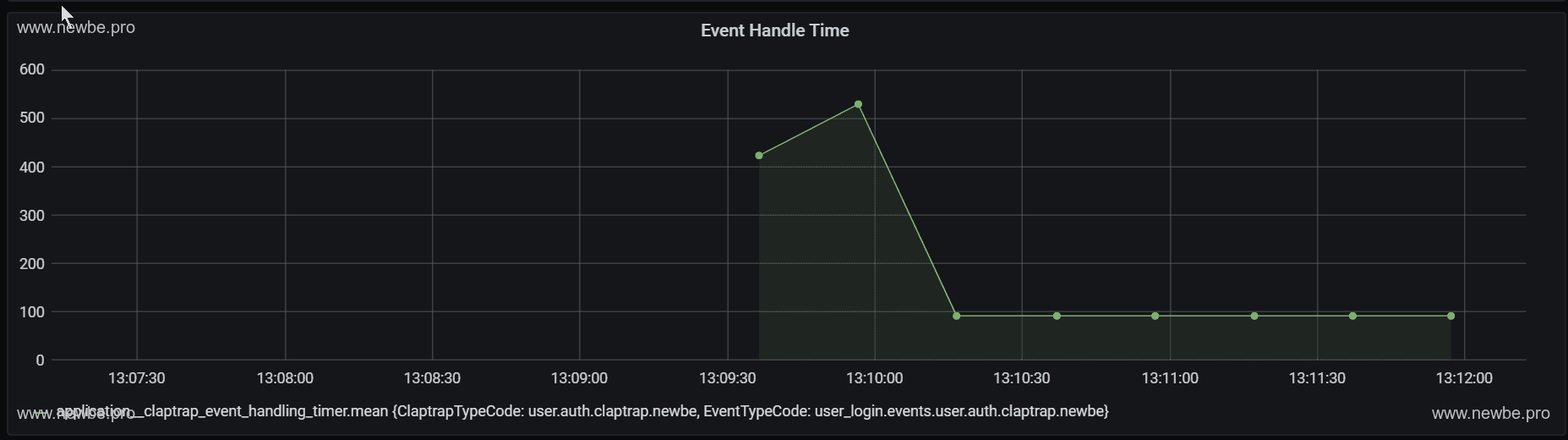
Grafana 中查看 Newbe.Claptrap 的事件的保存花费的平均时长约为 50-200 ms。事件的保存时长是事件处理的主要部分。

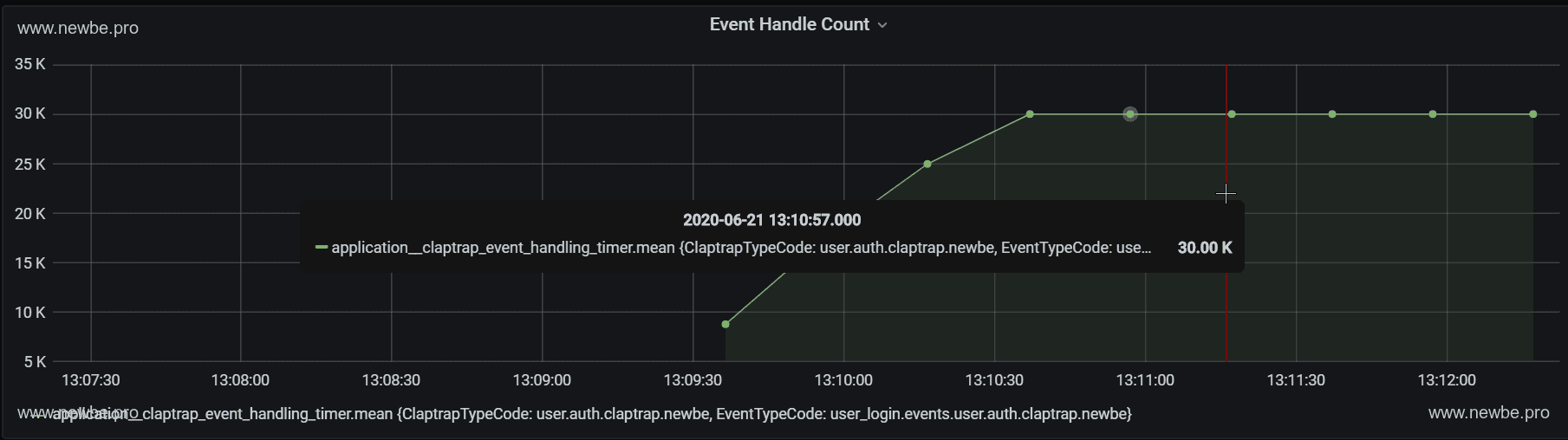
Grafana 中查看 Newbe.Claptrap 的事件已处理总数。一种登录了三万次,因此事件总数也是三万。
1 Gateway 1 Cluster
接下来,我们测试额外增加两个节点进行测试。
还是再提一下,Orleans 集群节点的数量实际上是 Cluster + Gateway + Dashboard 的总数。因此,对比上一个测试,该测试的节点数为 3。
测试得到的内存使用情况如下:
| 用户数 | 节点平均内存 | 内存总占用 |
|---|---|---|
| 10000 | 1.8 GB | 1.8*3 = 5.4 GB |
| 20000 | 3.3 GB | 3.3*3 = 9.9 GB |
| 30000 | 4.9 GB | 4.9*3 = 14.7 GB |
那么,以三万用户为例,平均每个用户占用的内存约为 (14.7*1024-200*3)/30000 = 0.48 MB
为什么节点数增加了,平均消耗内存上升了呢?笔者推测,没有进行过验证:节点增加,实际上节点之间的通讯还需要消耗额外的内存,因此平均来说有所增加。
3 Gateway 5 Cluster
我们再次增加节点。总结点数为 1 (dashboard) + 3 (cluster) + 5 (gateway) = 9 节点
测试得到的内存使用情况如下:
| 用户数 | 节点平均内�存 | 内存总占用 |
|---|---|---|
| 20000 | 1.6 GB | 1.6*9 = 14.4 GB |
| 30000 | 2 GB | 2*9 = 18 GB |
那么,以三万用户为例,平均每个用户占用的内存约为 (18*1024-200*9)/30000 = 0.55 MB
十万用户究竟要多少内存?
以上所有的测试都是以三万为用户数进行的测试,这是一个特殊的数字。因为继续增加用户数的话,内存将会超出测试机的内存余量。(求赞助两条 16G)
如果继续增加用户数,将会开始使用操作系统的虚拟内存。虽然可以运行,但是运行效率会降低。原来登录可能只需要 100 ms。使用到虚拟内存的用户则需要 2 s。
因此,速度降低的情况下,在验证需要多少内存意义可能不大。
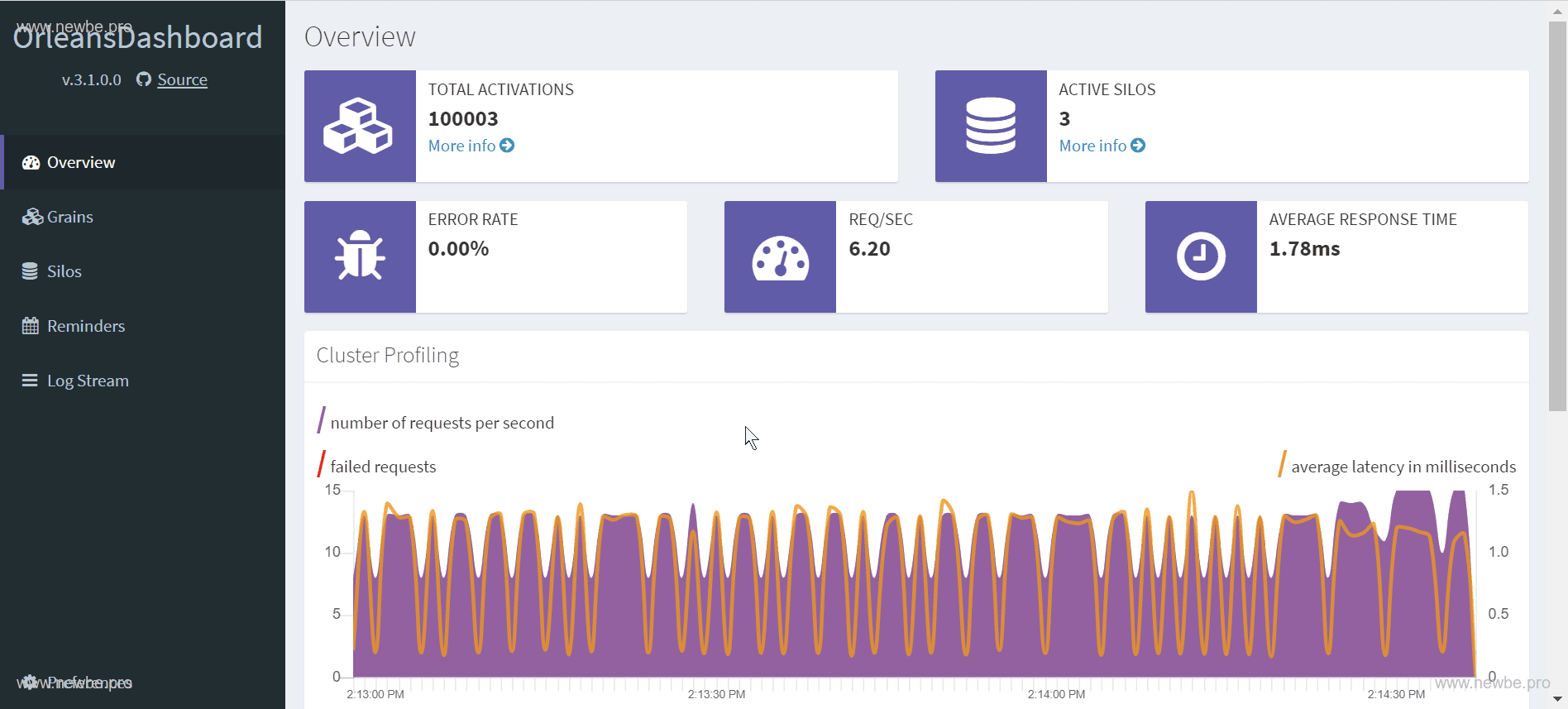
但是,这不意味着不能够继续登录,以下便是 1+1+1 的情况下,十万用户全部登录后的情况。(有十万用户同时在线,加点内存吧,不差钱了。)
源码构建说明
此次测试的代码均可以在文末的样例代码库中找到。为了方便读者自行实验,主要采用的是 docker-compose 进行构建和部署。
因此对于测试机的唯一环境需求就是要正确的安装好 Docker Desktop 。
可以从以下任一地址获取最新的样例代码:
快速启动
使用控制台进入 src/Newbe.Claptrap.Auth/LocalCluster 文件夹。运行以下命令便可以在本地启动所有的组件:
docker-compose up -d
途中需要拉取一些托管于 Dockerhub 上的公共镜像,请确保本地已经正确配置了相关的加速器,以便您可以快速构建。可以参看这篇文档进行设置
成功启动之后可以通过docker ps 查看到所有的组件。
PS>docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
66470e5393e2 registry.cn-hangzhou.aliyuncs.com/newbe36524/newbe-claptrap-auth-webapi "dotnet Newbe.Claptr…" 4 hours ago Up About an hour 0.0.0.0:10080->80/tcp localcluster_webapi_1
3bbaf5538ab9 registry.cn-hangzhou.aliyuncs.com/newbe36524/newbe-claptrap-auth-backendserver "dotnet Newbe.Claptr…" 4 hours ago Up About an hour 80/tcp, 443/tcp, 0.0.0.0:19000->9000/tcp, 0.0.0.0:32785->11111/tcp, 0.0.0.0:32784->30000/tcp localcluster_dashboard_1
3f60f51e4641 registry.cn-hangzhou.aliyuncs.com/newbe36524/newbe-claptrap-auth-backendserver "dotnet Newbe.Claptr…" 4 hours ago Up About an hour 80/tcp, 443/tcp, 9000/tcp, 0.0.0.0:32787->11111/tcp, 0.0.0.0:32786->30000/tcp localcluster_cluster_gateway_1
7d516ada2b26 registry.cn-hangzhou.aliyuncs.com/newbe36524/newbe-claptrap-auth-backendserver "dotnet Newbe.Claptr…" 4 hours ago Up About an hour 80/tcp, 443/tcp, 9000/tcp, 30000/tcp, 0.0.0.0:32788->11111/tcp localcluster_cluster_core_1
fc89fcd973f9 grafana/grafana "/run.sh" 4 hours ago Up 6 seconds 0.0.0.0:23000->3000/tcp localcluster_grafana_1
1f10ed0eb25f postgres "docker-entrypoint.s…" 4 hours ago Up About an hour 0.0.0.0:32772->5432/tcp localcluster_claptrap_db_1
d5d2bec74311 adminer "entrypoint.sh docke…" 4 hours ago Up About an hour 0.0.0.0:58080->8080/tcp localcluster_adminer_1
4c4be69f2f41 bitnami/consul "/opt/bitnami/script…" 4 hours ago Up About an hour 8300-8301/tcp, 8500/tcp, 8301/udp, 8600/tcp, 8600/udp localcluster_consulnode3_1
88811d3aa0d2 influxdb "/entrypoint.sh infl…" 4 hours ago Up 6 seconds 0.0.0.0:29086->8086/tcp localcluster_influxdb_1
d31c73b62a47 bitnami/consul "/opt/bitnami/script…" 4 hours ago Up About an hour 8300-8301/tcp, 8500/tcp, 8301/udp, 8600/tcp, 8600/udp localcluster_consulnode2_1
72d4273eba2c bitnami/consul "/opt/bitnami/script…" 4 hours ago Up About an hour 0.0.0.0:8300-8301->8300-8301/tcp, 0.0.0.0:8500->8500/tcp, 0.0.0.0:8301->8301/udp, 0.0.0.0:8600->8600/tcp, 0.0.0.0:8600->8600/udp localcluster_consulnode1_1
启动完成之后,便可以通过以下链接来查看相关的界面
| 地址 | 说明 |
|---|---|
| http://localhost:19000 | Orleans Dashboard 查看 Orleans 集群中各节点的状态 |
| http://localhost:10080 | Web API 基地址,此次使用所测试的 API 基地址 |
| http://localhost:23000 | Grafana 地址,查看 Newbe.Claptrap 相关的性能指标情况 |
源码构建
使用控制台进入 src/Newbe.Claptrap.Auth 文件夹。运行以下命令便可以在本地完成代码的构建:
./LocalCluster/pullimage.cmd
docker-compose build
pullimage.cmd 使用了笔者编写的 docker-mcr 加速器功能。您可以通过该文档来了解其工作原理
等待构建完毕之后,本地便生成好了相关的镜像。接下来便可以初次尝试在本地启动应用:
使用控制台进入 src/Newbe.Claptrap.Auth/LocalCluster 文件夹。运行以下命令便可以启动相关的容器:
docker-compose up -d
常见问题解答
文中为何没有说明代码和配置的细节?
本文主要为读者展示该方案的实验可行性,具体应该如何应用 Newbe.Claptrap 框架编写代码,并非本文的主旨,因此没有提及。
当然,另外一点就是目前框架没有最终定版,所有内容都有可能发生变化,讲解代码细节意义不大。
但可以提前说明的是:编写非常简单,由于本样例的业务需求非常简单,因此代码内容也不多。全部都可以在示例仓库中找到。
用 Redis 存储 Token 也可以实现上面的需求,为什么要选择这个框架?
目前来说,笔者没有十足的理由说服读者必须使用哪种方案,此处也只是提供一种可行方案,至于实际应该选择哪种方案,应该有读者自己来考量,毕竟工具是否趁手还是需要试试才知道。
如果是最多 100 个在线用户,那怎么裁剪系统?
必要的组件只有 Orleans Dashboard 、 WebAPI 和 Claptrap Db。其他的组件全部都是非必要的。而且如果修改代码, Orleans Dashboard 和 WebAPI 是可以合并的。
所以最小规模就是一个进程加一个数据库。
Grafana 为什么没有报表?
Grafana 首次启动之后需要手动的创建 DataSource 和导入 Dashboard.
本实验相关的参数如下:
DataSource
- URL: http://influxdb:8086
- Database: metricsdatabase
- User: claptrap
- Password: claptrap
测试机的物理配置是什么?
没有专门腾内存,未开始测试前已占用 16GB 内存。以下是测试机的身材数据(洋垃圾,3500 元左右):
处理器 英特尔 Xeon(至强) E5-2678 v3 @ 2.50GHz 12 核 24 线程 主板 HUANANZHI X99-AD3 GAMING ( Wellsburg ) 显卡 Nvidia GeForce GTX 750 Ti ( 2 GB / Nvidia ) 内存 32 GB ( 三星 DDR3L 1600MHz ) 2013 年产 高龄内存 主硬盘 金士顿 SA400S37240G ( 240 GB / 固态硬盘 )
如果您有更好的物理配置,相信可以得出更加优秀的数据。
即使是 0.3 MB 平均每用户的占用的我也觉得太高了
框架还在优化。未来会更好。
